Introduction
Cet article est une version actualisée de ce que j’avais publié dans GNU/Linux France Magazine numéro 163.
Voici ce que l’on souhaite obtenir :
- Un service utilisateur hautement disponible avec des serveurs de type Postfix, Apache, Zimbra, Dovecot, etc…
- Les serveurs de ces backends devront être en mode actif/actif afin de pouvoir fournir un système apte à monter en charge
- La haute disponibilité sera gérée par des load balancer qui ne devront pas être eux mêmes un SPOF, ils seront donc également load balancés
- Et pour être en phase avec la législation, les backends devront avoir en visibilité les adresses IP des clients et ce contrairement à un certain nombre d’architectures où le load balancer effectue du NAT et donc masque l’IP source.
Ces fonctionnalités sont disponibles via KeepAlived pour la HA du load balancer et HAProxy pour la HA des backends. Le mode transparent est lui accessible depuis le récent module kernel TPROXY dsponible sous Ubuntu depuis la release LTS 16.04.
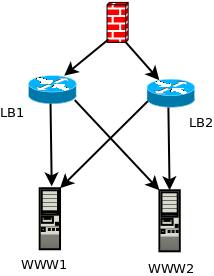
Architecture
Un impératif dans cette architecture c’est que les backends doivent être dans le même sous réseau que les load balancer. En effet, les serveurs load balancés auront comme passerelle la VIP des load balancer et non pas le firewall. 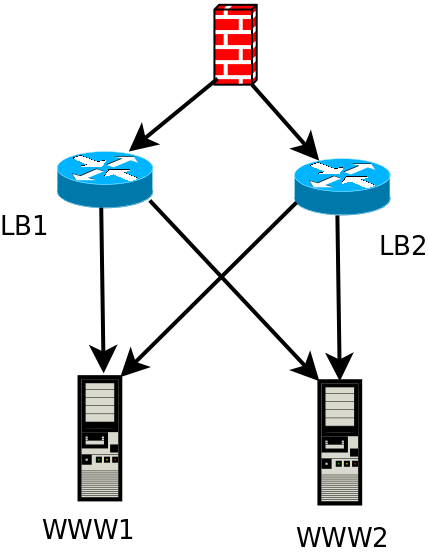
En pratique je vais avoir :
- www1 : Apache / Ubuntu 14.04, 192.169.69.106
- www2 : Apache / Ubuntu 14.04, 192.169.69.107
- lb1 : Apache / Ubuntu 16.04, 192.169.69.111
- lb2 : Apache / Ubuntu 16.04, 192.169.69.112
- La VIP 192.168.69.110
iMPORTANT, si vous devez tester depuis une machine du même sous-réseau, il y a une astuce! En effet, les paquets vont arriver aux serveurs load balancés via la VIP mais l’IP source étant sur le même subnet, la réponse dans ce cas se fera sans ressortir par le load balancer. Dans mon cas, ma machine a comme IP 192.168.69.104. Du coup, sur chaque serveur load balancés, il est nécessaire d’ajouter une règle comme suit :
ip route add 192.168.69.104/32 via 192.168.69.110
Haute disponibilité du load balancer
On commence sur les deux load balancer à installer KeepAlived qui fournira les fonctionnalités de cluster VRRP :
apt-get install keepalived haproxy hatop systemctl enable keepalived.service systemctl enable haproxy.service echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf echo "net.ipv4.ip_nonlocal_bind=1" >> /etc/sysctl.conf sysctl -p /etc/sysctl.conf
Il nous faut configurer notre cluster VRRP dans le fichier /etc/keepalived/keepalived.conf. Attention au nom de l’interface réseau dans ce fichier.
Sur le master :
vrrp_script reload_haproxy {
script "killall -0 haproxy"
interval 1
}
vrrp_instance VI_1 {
virtual_router_id 100
state MASTER
priority 100
# Check inter-load balancer toutes les 1 secondes
advert_int 1
# Synchro de l'état des connexions entre les LB sur l'interface enp0s3
lvs_sync_daemon_interface enp0s3
interface enp0s3
# Authentification mutuelle entre les LB, identique sur les deux membres
authentication {
auth_type PASS
auth_pass secret
}
# Interface réseau commune aux deux LB
virtual_ipaddress {
192.168.69.110/32 brd 192.168.69.255 scope global
}
track_script {
reload_haproxy
}
}
Sur le Slave, c’est à peu près le même fichier :
vrrp_script reload_haproxy {
script "killall -0 haproxy"
interval 1
}
vrrp_instance VI_1 {
virtual_router_id 100
state BACKUP
priority 100
# Check inter-load balancer toutes les 1 secondes
advert_int 1
# Synchro de l'état des connexions entre les LB sur l'interface enp0s3
lvs_sync_daemon_interface enp0s3
interface enp0s3
# Authentification mutuelle entre les LB, identique sur les deux membres
authentication {
auth_type PASS
auth_pass secret
}
# Interface réseau commune aux deux LB
virtual_ipaddress {
192.168.69.110/32 brd 192.168.69.255 scope global
}
track_script {
reload_haproxy
}
}
Le premier des deux load balancer va récupérer l’adresse de la VIP :
root@lb1:~# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:68:44:b0 brd ff:ff:ff:ff:ff:ff
inet 192.168.69.111/24 brd 192.168.69.255 scope global enp0s3
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fe68:44b0/64 scope link
valid_lft forever preferred_lft forever
Le redémarrage du service keepalived ou le reboot du serveur permettant de tester que la VIP bascule bien sur lb2 :
Sep 18 21:53:00 lb2 Keepalived_vrrp[18740]: VRRP_Instance(VI_1) Transition to MASTER STATE Sep 18 21:53:01 lb2 Keepalived_vrrp[18740]: VRRP_Instance(VI_1) Entering MASTER STATE
Les serveurs load balancés
Seule configuration, définir la VIP comme passerelle par défaut!
HAProxy
Contrairement à mon article dans GLMF 163, ici c’est le célèbre HAProxy qui est utilisé pour réaliser le load balancing. HAProxy dispose de deux modes, http ce qui lui permet de traiter et de manipuler finement ce protocole et gère également l’offload SSL. Le second mode est le mode TCP qui permet ainsi de load balancer n’importe quel protocole de niveau supérieur basé sur TCP qui a ma préférence.
Premièrement, il faut faire un peu d’iptables avec que haproxy puisse identifier les paquets rattachés à une socket non locale ce qui est parfaitement documenté dans les sources du kernel.
Sur chaque load balancer on fait donc ceci (qui peut être placé dans le fichier /etc/rc.local ou un script d’init dédié) :
iptables -t mangle -N DIVERT iptables -t mangle -A PREROUTING -p tcp -m socket -j DIVERT iptables -t mangle -A DIVERT -j MARK --set-mark 1 iptables -t mangle -A DIVERT -j ACCEPT ip rule add fwmark 1 lookup 100 ip route add local 0.0.0.0/0 dev lo table 100
Enfin, on paramètre haproxy avec le même fichier /etc/haproxy/haproxy.cfg sur les deux load balancer. Seul défaut du mode transparent, c’est que haproxy doit tourner en root :
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin
stats timeout 30s
user root
group root
daemon
defaults
log global
mode tcp
timeout connect 5000
timeout client 50000
timeout server 50000
frontend ft_http
bind :80 transparent
mode tcp
default_backend bk_http
backend bk_http
mode tcp
balance leastconn
stick store-request src
stick-table type ip size 200k expire 30m
source 0.0.0.0 usesrc clientip
server s1 192.168.69.106:80
server s1 192.168.69.107:80
frontend ft_https
bind :443 transparent
mode tcp
default_backend bk_https
backend bk_https
mode tcp
balance leastconn
stick store-request src
stick-table type ip size 200k expire 30m
source 0.0.0.0 usesrc clientip
server s1 192.168.69.106:443
server s1 192.168.69.107:443
Il ne reste plus qu’à redémarrer le service haproxy pour prise en compte, et voila!
Bonsoir,
Pourquoi ne pas utiliser le proxy-protocol d’HAProxy en mode HTTP pour préserver les informations clientes au lieu d’utiliser iptables et le mode tcp plus coûteux ?
Cordialement
Car c’est juste pour l’exemple 😉
L’idée étant de présenter l’architecture, pas haproxy. Du coup, c’est plus simple de maquetter.
Julien
Pourquoi haproxy (certes très bien pour faire, par exemple, du reverse…) ?
Keepalived ne se suffit-il pas à lui-même ?
# Interface réseau commune aux deux LB
virtual_ipaddress {
192.168.69.110/32 brd 192.168.69.255 scope global
}
virtual_server 192.168.69.106 443 {
lb_algo wrr
lb_kind DR
protocol TCP
delay_loop 15
persistence_timeout 50
virtualhost my.domain
real_server 192.168.69.106 443 {
weight 1
inhibit_on_failure
HTTP_GET {
url {
path https://my.domain1
status_code 200
}
connect_timeout 2
nb_get_retry 1
delay_before_retry 1
}
}
real_server 192.168.69.106 443 {
weight 1
inhibit_on_failure
HTTP_GET {
url {
path https://my.domain2
status_code 200
}
connect_timeout 2
nb_get_retry 1
delay_before_retry 1
}
}
}
…
Sans oublier dans la config réseau des noeuds (qui doivent en effet répondre eux-mêmes aux clients avec l’ip du cluster) :
auto lo:27
iface lo:27 inet static
address 192.168.69.106
netmask 255.255.255.255
J’ai fait un cluster de proxies squid sur ce modèle et keepalived fonctionne excellemment (en mode transparent également) …
Sorry : j’avais pas vu le lien « GLMF-163″… 😉
Pas de soucis 🙂
Haproxy c’est malgré tout un niveau au dessus de keepalived en terme de fonctionnalités. Pour le HTTP que tu cites en exemple, tu peux faire de l’offload SSL ce que ne permet pas keepalived.
Je suis d’accord, keepalived est sympa pour implémenter VRRP mais pour le reste… c’est un peu vieillot. Sans compter sur les ACL HAProxy en HTTP, sacrée feature.
A+
Ça coûte quoi de mettre en place une telle architecture chez OVH ?
Petite question … sur ce vieux thread 🙂
un master master sur keepalive avec des priority en accord … ce ne serait pas mieux ?
Dès que le second noeud du cluster VRRP devient actif, une élection est déclenchée et la priorité a donc une influence plus importante que le paramètre state. En pratique, c’est juste un état initial au démarrage du service qui est défini et donc maitrisé (en complément du fallback éventuel sur le master). Les deux configurations sont donc possibles mais sans grande différence.
bonjour
merci pour l’article
j’ai une problème lorsque je redemande keepalived voila ce q’il m’affiche
● keepalived.service – Keepalive Daemon (LVS and VRRP)
Loaded: loaded (/lib/systemd/system/keepalived.service; enabled; vendor preset: enabled)
Active: active (running) since jeu. 2018-10-11 12:33:05 CEST; 6min ago
Process: 7883 ExecStart=/usr/sbin/keepalived $DAEMON_ARGS (code=exited, status=0/SUCCESS)
Main PID: 7885 (keepalived)
Tasks: 3
Memory: 1.0M
CPU: 4.111s
CGroup: /system.slice/keepalived.service
├─7885 /usr/sbin/keepalived
├─7887 /usr/sbin/keepalived
└─7888 /usr/sbin/keepalived
oct. 11 12:33:05 vps595468 Keepalived_vrrp[7888]: Opening file ‘/etc/keepalived/keepalived.conf’.
oct. 11 12:33:05 vps595468 Keepalived_vrrp[7888]: (VI_1): Specifying lvs_sync_daemon_interface against a vrrp is deprecated.
oct. 11 12:33:05 vps595468 Keepalived_vrrp[7888]: Please use global lvs_sync_daemon
oct. 11 12:33:05 vps595468 Keepalived_vrrp[7888]: Initializing ipvs
oct. 11 12:33:05 vps595468 Keepalived_vrrp[7888]: Using LinkWatch kernel netlink reflector…
oct. 11 12:33:05 vps595468 Keepalived_vrrp[7888]: VRRP_Script(reload_haproxy) succeeded
oct. 11 12:33:06 vps595468 Keepalived_vrrp[7888]: VRRP_Instance(VI_1) Transition to MASTER STATE
oct. 11 12:33:07 vps595468 Keepalived_vrrp[7888]: VRRP_Instance(VI_1) Entering MASTER STATE
oct. 11 12:33:07 vps595468 Keepalived_vrrp[7888]: IPVS: No such file or directory
oct. 11 12:33:07 vps595468 Keepalived_vrrp[7888]: IPVS: Daemon has already run
l’orsque je fait un reboot le vps lbn pour test le lbn1 slave il marche bien si il ya une probleme sur le lbn2 mai ca ne marche plus comme si il na pas de basculement du coup pas de cluster
Le « IPVS: No such file or directory » n’est pas normal. Tente de lancer keepalived sans passer par le script d’init : keepalived -f /etc/keepalived/keepalived.conf -l -n -D par exemple.
Bonjour,
Nous avons un soucis avec l’ip virtuelle de Keepalived : elle ne répond pas au ping.
L’ip virtuelle est bien attribuée, la bascule sur l’un des deux noeuds se fait bien lorsqu’on coupe le service.
Noeud 1 :
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 51
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.114.132/24
}
}
Noeud 2 :
vrrp_instance VI_1 {
state BACKUP
interface ens160
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.114.132/24
}
}
On voit que le noeud 1 récupére bien l’ip virtuelle :
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:50:56:b7:61:86 brd ff:ff:ff:ff:ff:ff
inet 192.168.114.130/24 brd 192.168.114.255 scope global noprefixroute ens160
valid_lft forever preferred_lft forever
inet 192.168.114.132/24 scope global secondary ens160
valid_lft forever preferred_lft forever
inet6 fe80::fcf9:444c:a94a:f53e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
Nous avons rajouté ces lignes dans les fichiers sysctl.conf:
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.conf.ens160.arp_ignore = 1
net.ipv4.conf.ens160.arp_announce = 2
Service Firewalld désactivé..
Si quelqu’un a une piste…
Merci beaucoup
Bonjour Nicolas,
Pas simple de se prononcer à distance, mais plusieurs points me viennent à l’exprit :
– voir si un /proc/sys/net/ipv4/conf/all n’est pas défini
– vérifier également que le rp_filter ne drop pas les paquets : https://access.redhat.com/solutions/53031
– même si firewalld est désactivé, vérifie que toutes les tables et chaines iptables sont flushées
– aucune route ne s’est ajoutée ?
Julien
Bonjour Merci pour l’article
j’ai configuré VRRP très bien la VIP bascule parfaitement par contre impossible de router les flux au niveau de chaque HAproxy.
Lorsqu’on veut envoyer une requête (même d’un autre réseau) sur la VIP on a bien un SYN mais pas de ACK le routage bloque au niveau du HAproxy.
Si l’on retire source 0.0.0.0 usesrc clientip c’est ok mais on perd l’intérêt du TPROXY…
Je précise que les deux HAproxy et mes backends sont sur le mm subnet et je n’ai pas configuré de route spécifique ni sur mon backend ni sur les proxies.
J’ai tester de positionner le default gateway de mes backend avec la VIP mais sans succès.
Bonjour Fabrice,
Je te réponds tardivement, je rentre juste de vacances. Vérifie que les règles iptables et ip route ne sont pas masquées par une autre de plus forte priorité et que haproxy est bien compilé avec l’option TPROXY.
Julien